User's Guide
If you are new to OpenCL, begin by reading about its architecture in Chapter 3 of the OpenCL Specification.
1 Parallel sum
Consider a monoatomic gas with molecules of mass in equilibrium at temperature . From the equipartition theorem we know that in the thermodynamic limit, , the average kinetic energy of a molecule with three degrees of freedom is . We will estimate the energy through parallel summation of molecule velocities, .
The program begins with setting up the OpenCL environment:
local platform = cl.get_platforms()[1]
local device = platform:get_devices()[1]
local context = cl.create_context({device})
local queue = context:create_command_queue(device)Each platform corresponds to an OpenCL driver and provides one or more devices. A context is created on one or more devices of the same platform. In a context we can allocate memory buffers that are shared among all devices of that context. The OpenCL driver copies contents of buffers between devices when needed, for example between the host and a discrete GPU. Commands that read, write and copy buffers, or execute computations on a device, are scheduled in command queues. By default, commands are executed in order of submission to a queue.
We prepare the system by choosing the velocities of the molecules from a Maxwell-Boltzmann distribution with temperature , which is the standard normal distribution. We map the buffer that stores the velocities for writing, which yields a pointer that is accessible by the host program, write the velocities and unmap the buffer.
local N = 1000000
local d_v = context:create_buffer(N * ffi.sizeof("cl_double3"))
local v = ffi.cast("cl_double3 *", queue:enqueue_map_buffer(d_v, true, "write"))
for i = 0, N - 1, 2 do
v[i].x, v[i + 1].x = random.normal()
v[i].y, v[i + 1].y = random.normal()
v[i].z, v[i + 1].z = random.normal()
end
queue:enqueue_unmap_mem_object(d_v, v)On a CPU, unmapping the buffer has no impact. On a discrete GPU, the contents of the buffer are copied to the device.
With OpenCL a computation is partitioned into a given number of work items. Work items are arranged into work groups of a given work-group size. Work items that belong to the same work group may exchange data via local memory with low latency.
For the parallel summation we choose work dimensions of powers of two:
local work_size = 128
local num_groups = 512
local glob_size = num_groups * work_sizeThe optimal work dimensions need to be determined by performing measurements of the run-time. Although the optimal work dimensions vary from device to device, modern GPUs for example have similar architectures with thousands of scalar cores, and a single set of work dimensions can yield close to optimal run-times across different GPUs.
Each work item independently computes a partial sum, which reduces the number of summands from the number of molecules (1000000) to the global number of work items (65536). The partial sums are stored in local memory and gradually summed in a pairwise manner. At each step the number of work items that carry out an addition reduces by half, while the other work items idle.

Note how in each step the collective memory accesses of work items within a group are contiguous. This linear pattern is generally the most efficient memory access pattern, whether accessing local memory of low latency or global memory of high latency.
The OpenCL C kernel that sums the molecule velocities is included in the Lua program:
local temp = templet.loadstring[[
#ifndef CL_VERSION_1_2
#pragma OPENCL EXTENSION cl_khr_fp64 : enable
#endif
__kernel void sum(__global const double3 *restrict d_v,
__global double *restrict d_en)
{
const long gid = get_global_id(0);
const long lid = get_local_id(0);
const long wid = get_group_id(0);
__local double l_en[${work_size}];
double en = 0;
for (long i = gid; i < ${N}; i += ${glob_size}) {
en += dot(d_v[i], d_v[i]);
}
l_en[lid] = en;
barrier(CLK_LOCAL_MEM_FENCE);
|local i = work_size
|while i > 1 do
| i = i / 2
if (lid < ${i}) l_en[lid] += l_en[lid + ${i}];
barrier(CLK_LOCAL_MEM_FENCE);
|end
if (lid == 0) d_en[wid] = l_en[0];
}
]]The kernel code contains Lua expressions ${...} and
statements |.... Before compiling the kernel for the
device, we preprocess the code with Templet to substitute
parameters such as the number of molecules N and unroll
parallel summing.
After template expansion the code for parallel summing becomes
if (lid < 64) l_en[lid] += l_en[lid + 64];
barrier(CLK_LOCAL_MEM_FENCE);
if (lid < 32) l_en[lid] += l_en[lid + 32];
barrier(CLK_LOCAL_MEM_FENCE);
if (lid < 16) l_en[lid] += l_en[lid + 16];
barrier(CLK_LOCAL_MEM_FENCE);
if (lid < 8) l_en[lid] += l_en[lid + 8];
barrier(CLK_LOCAL_MEM_FENCE);
if (lid < 4) l_en[lid] += l_en[lid + 4];
barrier(CLK_LOCAL_MEM_FENCE);
if (lid < 2) l_en[lid] += l_en[lid + 2];
barrier(CLK_LOCAL_MEM_FENCE);
if (lid < 1) l_en[lid] += l_en[lid + 1];
barrier(CLK_LOCAL_MEM_FENCE);Between each summation step the work items of a group are synchronized using a local-memory barrier that ensures a consistent state among work items of the contents of local memory after the barrier. Since the compiler knows exactly which work items are summing and which are idling, it is able to optimize away unneeded synchronization points. On GPUs, work items within groups of 64 or 32, depending on the vendor, operate in lock-step and do not require explicit synchronization.
In the host program we preprocess and compile the OpenCL C source code:
local source = temp({N = N, work_size = work_size, glob_size = glob_size})
local program = context:create_program_with_source(source)
local status, err = pcall(function() return program:build() end)
io.stderr:write(program:get_build_info(device, "log"))
if not status then error(err) endThe call to program:build() is wrapped with pcall to
intercept a potential build failure and output compiler messages before
raising an error. We are also interested in compiler messages if the
program build succeeds, since it may contain non-fatal warnings that
hint programming errors.
Once the program is built we acquire and execute the sum
kernel function:
local kernel = program:create_kernel("sum")
local d_en = context:create_buffer(num_groups * ffi.sizeof("cl_double"))
kernel:set_arg(0, d_v)
kernel:set_arg(1, d_en)
queue:enqueue_ndrange_kernel(kernel, nil, {glob_size}, {work_size})The kernel receives an input buffer with the velocities and an output buffer that stores the partial sum of each work group.
Finally we map the buffer for reading on the host and compute the average kinetic energy per molecule.
local sum = 0
local en = ffi.cast("cl_double *", queue:enqueue_map_buffer(d_en, true, "read"))
for i = 0, num_groups - 1 do sum = sum + en[i] end
queue:enqueue_unmap_mem_object(d_en, en)
print(0.5 * sum / N)1.4977721207647The result is close to the exact energy of within the error of .
2 Mandelbrot set
In this example we will compose an OpenCL program that calculates the Mandelbrot set. The Mandelbrot set is the set of points in the complex plane for which the limit of the infinite recursion , is bounded, i.e. as the number of recursions .
Since our computer time is finite, we limit the problem to a finite number of recursions and introduce an escape radius : if the distance of the point from the origin after recursions, the point is not in the Mandelbrot set; otherwise, if after recursions, the point is in the Mandelbrot set. The calculation of the Mandelbrot set is a good example for a numerical algorithm that is trivial to parallelize, since the recursion can be carried out independently for each point.
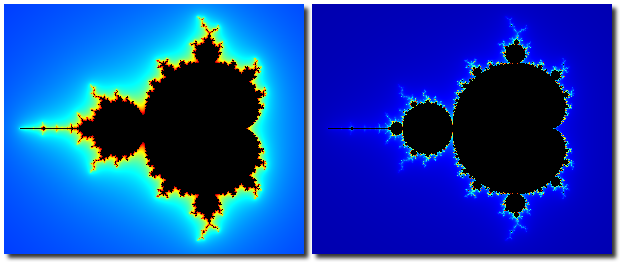
The figure shows the complex plane with points in the Mandelbrot set colored in black and points not in the Mandelbrot set colored according to the number of recursions before escaping , ranging from blue for to red for .
After installing OpenCL for Lua and the Templet preprocessor, try running the program:
./mandelbrot.lua config.luaThis generates an image in the portable pixmap format, which can be shown using
display mandelbrot.ppmor converted to a compressed image format with
convert mandelbrot.ppm mandelbrot.pngWe begin with the file config.lua that contains the
parameters.
-- range of x = Re(z)
X = {-1.401155 - 0.75, -1.401155 + 2.25}
-- range of y = Im(z)
Y = {-1.25, 1.25}
-- number of horizontal pixels
Nx = 5120
-- number of vertical pixels
Ny = math.ceil(Nx * (Y[2] - Y[1]) / (X[2] - X[1]))
-- number of recursions
N = 100
-- escape radius
R = 100
-- PPM image filename
output = "mandelbrot_N" .. N .. ".ppm"
-- OpenCL platform
platform = 1
-- OpenCL device
device = 1Since the configuration is itself written in Lua, we may derive
parameters in place, such as the number of vertical pixels needed for a
proportional image, or an output filename that denotes the number of
recursions. The ranges in the complex plane are given as coordinate
offsets to a Feigenbaum
point of the Mandelbrot set,
.
To explore the self-similarity of
the Mandelbrot fractal, try zooming in
around the Feigenbaum point by decreasing the offsets in X
and Y while increasing N.
We begin the program mandelbrot.lua by loading the
configuration into a table.
local config = setmetatable({}, {__index = _G})
loadfile(arg[1], nil, config)()Setting the metatable of the table config to the global
environment (_G) before invoking loadfile
provides mathematical and other functions of the Lua standard library in
the configuration.
Next we load the OpenCL C source code that contains the calculation:
local template = templet.loadfile("mandelbrot.cl")
local source = template(config)The source code is parsed by the Templet preprocessor,
which substitutes the parameters of the table config in the
source code. We will see later how the use of a template preprocessor
may improve the efficiency and the readability of an OpenCL program.
The OpenCL environment is set up by selecting one of the available platforms, with each platform corresponding to a different OpenCL driver, selecting one of the devices available on that platform, and creating a context on that device.
local platform = cl.get_platforms()[config.platform]
local device = platform:get_devices()[config.device]
local context = cl.create_context({device})Then we compile the OpenCL C source code to a binary program:
local program = context:create_program_with_source(source)
local status, err = pcall(function() return program:build() end)
io.stderr:write(program:get_build_info(device, "log"))
if not status then error(err) endThe function program.build is invoked using a protected
call to be able to write the build log to the standard error output,
before raising an error in case the build has failed. The build log is
useful in any case, since it includes non-fatal warning messages.
We allocate a memory buffer to store the Mandelbrot image:
local Nx, Ny = config.Nx, config.Ny
local d_image = context:create_buffer(Nx * Ny * ffi.sizeof("cl_uchar3"))The pixels of the image are represented as red-green-blue tuples
(RGB), with each color intensity in the integer range 0 to 255. A pixel
is stored as a 3-component vector of type cl_uchar3. Vector
types are aligned to powers of two bytes in memory space for efficiency
reasons; which means cl_uchar3 is aligned to 4 bytes, and
each pixel within the buffer is padded with an unused byte. This becomes
important later when we save the image to a file.
We create a kernel object for the device function
mandelbrot:
local kernel = program:create_kernel("mandelbrot")
kernel:set_arg(0, d_image)The function receives the memory buffer as its sole argument; recall we substituted constant parameters earlier using the template preprocessor. For parameters that vary in time, kernel arguments may also be passed by value.
To execute the device function we enqueue the kernel in a command queue:
local queue = context:create_command_queue(device, "profiling")
local event = queue:enqueue_ndrange_kernel(kernel, nil, {Nx, Ny}, {64, 1})Queue functions are asynchronous or non-blocking with only few exceptions, i.e., the function that enqueues the command returns immediately while the command is executed in the background. Enqueued commands are executed in order by default. A queue function returns an event associated with the enqueued command, which other commands enqueued in different queues may depend on. Here we store the event associated with the kernel to later query its execution time.
The mandelbrot kernel is executed on a two-dimensional
grid of dimensions {Nx, Ny}, where each pixel of the image
is mapped to one work item. Work items are divided into work groups, and
the number of work items per work group can be specified explicitly.
Work items that belong to the same work group may communicate via
synchronization points and local memory.
Next we map the memory buffer containing the image to a host pointer:
local image = ffi.cast("cl_uchar3 *", queue:enqueue_map_buffer(d_image, true, "read"))By passing true as the second argument we specify
that the map command is synchronous: the function will block until the
data is available for reading on the host. The function returns a
void pointer, which we cast to the vector type
cl_char3 to read the elements of the buffer.
Mapping a buffer for reading and/or writing has the advantage that the data is only copied between the device and the host if needed; for instance the data need not be copied when the device and the host share the same memory, which is the case for a CPU device or an integrated GPU device.
We output the image of the Mandelbrot set to a file:
local f = io.open(config.output, "w")
f:write("P6\n", Nx, " ", Ny, "\n", 255, "\n")
local row = ffi.new("struct { char r, g, b; }[?]", Nx)
for py = 0, Ny - 1 do
for px = 0, Nx - 1 do
row[px].r = image[px + py * Nx].s0
row[px].g = image[px + py * Nx].s1
row[px].b = image[px + py * Nx].s2
end
f:write(ffi.string(row, Nx * 3))
end
f:close()Recall that cl_char3 is aligned to 4 bytes, while the
binary portable pixmap format requires pixels to be aligned to 3 bytes.
For each row of pixels we copy the color intensities from the OpenCL
buffer to an intermediate array before writing the row to the file.
The buffer is unmapped after use:
queue:enqueue_unmap_mem_object(d_image, image)To measure the run-time of the kernel, we query the captured events:
local start = event:get_profiling_info("start")
local stop = event:get_profiling_info("end")
io.write(("%.4g s\n"):format(tonumber(stop - start) * 1e-9))The profiling times are returned in nano-seconds since an arbitrary reference time on the device. After calculating the interval between “start” and “end” times, which are 64 bit integers, we convert it to a Lua number and output the time in seconds.
Finally we consider the OpenCL C code in the file
mandelbrot.cl.
__kernel void mandelbrot(__global uchar3 *restrict d_image)The kernel receives the output buffer for the image as an argument.
Note the element type is uchar3 in the kernel code, while
we used cl_uchar3 in the host code above. OpenCL defines a
comprehensive set of scalar
and vector
data types, where the types are used without a cl_ prefix
in the kernel code and with a cl_ prefix in the host code.
OpenCL data types maintain the same sizes across platforms, e.g.,
cl_int always has 32 bits and cl_long always
has 64 bits.
Kernel arguments for arrays should always include the pointer
qualifier restrict, which hints the compiler that the
memory of one array does not overlap with the memory of other arrays,
i.e., the respective pointers do not alias. This
allows the compiler to generate efficient code, for instance reading an
array element that is used multiple times only once.
The kernel begins by querying the coordinates of the work item on the grid:
const uint px = get_global_id(0);
const uint py = get_global_id(1);
const double x0 = ${X[1]} + ${(X[2] - X[1]) / Nx} * px;
const double y0 = ${Y[1]} + ${(Y[2] - Y[1]) / Ny} * (${Ny - 1} - py);The coordinates px and py correspond to the
horizontal and vertical pixel coordinate within the image, which are
converted to the point
in the complex plane. Here we make use of the template preprocessor to
substitute the ranges in the complex plane and precompute the conversion
factors. The expressions enclosed in ${...} contain Lua
code that is evaluated during template preprocessing.
After template preprocessing the above kernel code may look as follows:
const uint px = get_global_id(0);
const uint py = get_global_id(1);
const double x0 = -2.151155 + 0.0006 * px;
const double y0 = -1.25 + 0.00059995200383969 * (4166 - py);The expanded code no longer contains any division, which is usually slower than multiplication. We avoid passing many constants as additional kernel arguments, or scattering the precomputation of constants in the host code. Besides yielding a compact kernel that aids the compiler with optimization, the code is closer to the mathematical formulation of the algorithm and becomes easier to understand and maintain.
We proceed with the Mandelbrot recursion:
double x = 0;
double y = 0;
uchar3 rgb = (uchar3)(0, 0, 0);
for (int n = 0; n < ${N}; ++n) {
const double x2 = x * x;
const double y2 = y * y;
const float r2 = x2 + y2;
if (r2 > (float)(${R ^ 2})) {
const float f = log2(log(r2) * (float)(${0.5 / math.log(R)}));
const float s = (n + 1 - f) * (float)(${1 / N});
rgb = colormap(s);
break;
}
y = 2 * x * y + y0;
x = x2 - y2 + x0;
}If the point exceeds the escape radius
,
the number of recursions is converted to a color using smooth
coloring, which avoids visible bands by converting the radius of the
escaped point to a scale-invariant value in
that is added to the recursion count. The fractional number of
recursions is converted to an RGB tuple using the colormap
function.
uchar3 colormap(float s)
{
const float3 t = s - (float3)(0.75, 0.5, 0.25);
const float3 c = (float)(${1.5 * 256}) - fabs(t) * (float)(${4 * 256});
return convert_uchar3_sat(c);
}Note that calls to device functions within a kernel are inlined by
the compiler. The function takes a scalar intensity and returns an RGB
tuple obtained from the superposition of linear segments of red, green,
and blue. OpenCL provides vector algebra functions for vector types,
which we use to derive the three color intensities. The conversion
function convert_uchar3_sat truncates each intensity to
before converting from floating point to 8 bit integer.
The Mandelbrot code serves as an example for mixed-precision
floating-point calculation. The recursion is evaluated in double
precision to maintain numerical stability of the algorithm. For the
color conversion we resort to single precision, which matches the
accuracy of an RGB tuple. Note the pre-computed constants are enclosed
in (float)(...), which converts double-precision numbers
generated by the template preprocessor to single precision.
We end the kernel by storing the RGB tuple to the output buffer:
d_image[px + py * ${Nx}] = rgb;Note how work items with consecutive coordinate px
access global memory in a contiguous manner. The linear pattern allows
the device to group the memory accesses of multiple work items into one
collective memory access. Global memory may have a latency on the order
of 1000 clock cycles; therefore it should be used as sparingly and
efficiently as the algorithm allows.